Vidushraj
 A dedicated and experienced Data professional with 4 years of expertise in Data engineering & Data science. Passionate about exploring new technologies & techniques in data engineering to drive innovation & achieve business objectives.
A dedicated and experienced Data professional with 4 years of expertise in Data engineering & Data science. Passionate about exploring new technologies & techniques in data engineering to drive innovation & achieve business objectives. View My Portfolio
View My GitHub Profile
Portfolio
Data Analytics with PySpark
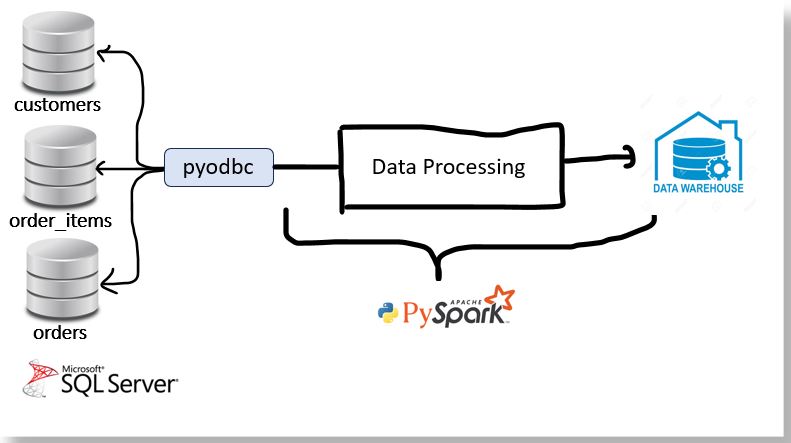 In this endeavor, we aim to explore the utilization of Apache Spark for deriving valuable insights from a relational database. With three distinct data tables at our disposal, we engage in foundational join operations to amalgamate these tables, culminating in the creation of a denormalized data frame. This structured approach enables us to conduct further processing and analytics with ease, unlocking the potential inherent in our dataset.
In this endeavor, we aim to explore the utilization of Apache Spark for deriving valuable insights from a relational database. With three distinct data tables at our disposal, we engage in foundational join operations to amalgamate these tables, culminating in the creation of a denormalized data frame. This structured approach enables us to conduct further processing and analytics with ease, unlocking the potential inherent in our dataset.
Power BI Projects
 This novypro websites showcases a dynamic array of Power BI dashboards, offering insightful visualizations and analysis of data trends. Explore the latest innovations and emerging trends in Power BI.
This novypro websites showcases a dynamic array of Power BI dashboards, offering insightful visualizations and analysis of data trends. Explore the latest innovations and emerging trends in Power BI.
Build ETL Pipeline with PySpark
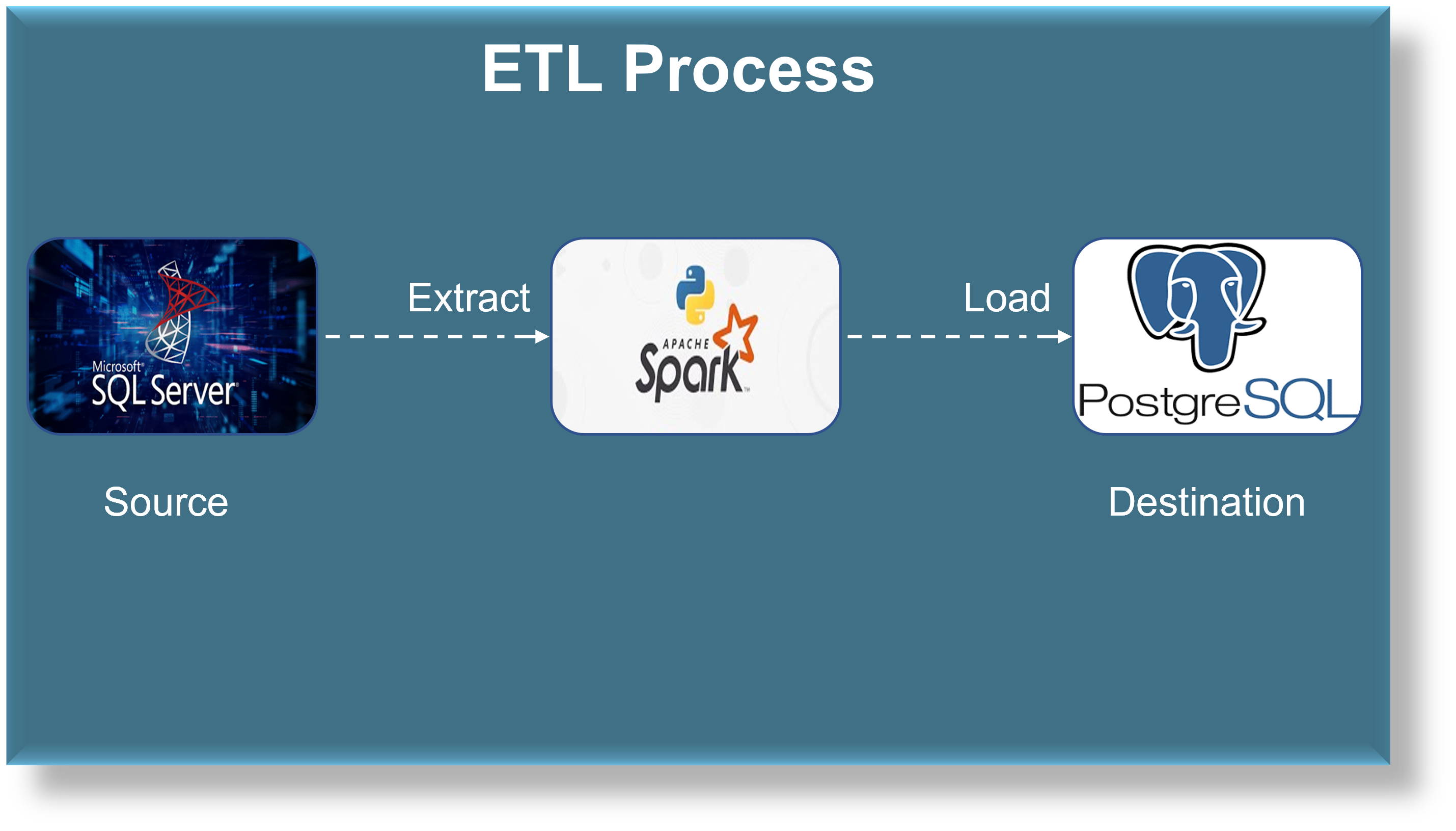 This project involves building an ETL pipeline using Pyspark to extract data from a SQL Server database and load it into a PostgreSQL database. Pyspark’s data processing features will be utilized to perform efficient data transformations. The aim is to develop a scalable and efficient ETL pipeline for seamless data integration between the two databases.
This project involves building an ETL pipeline using Pyspark to extract data from a SQL Server database and load it into a PostgreSQL database. Pyspark’s data processing features will be utilized to perform efficient data transformations. The aim is to develop a scalable and efficient ETL pipeline for seamless data integration between the two databases.
End to End Automated Data Pipeline using Snowflake, AWS & Airflow
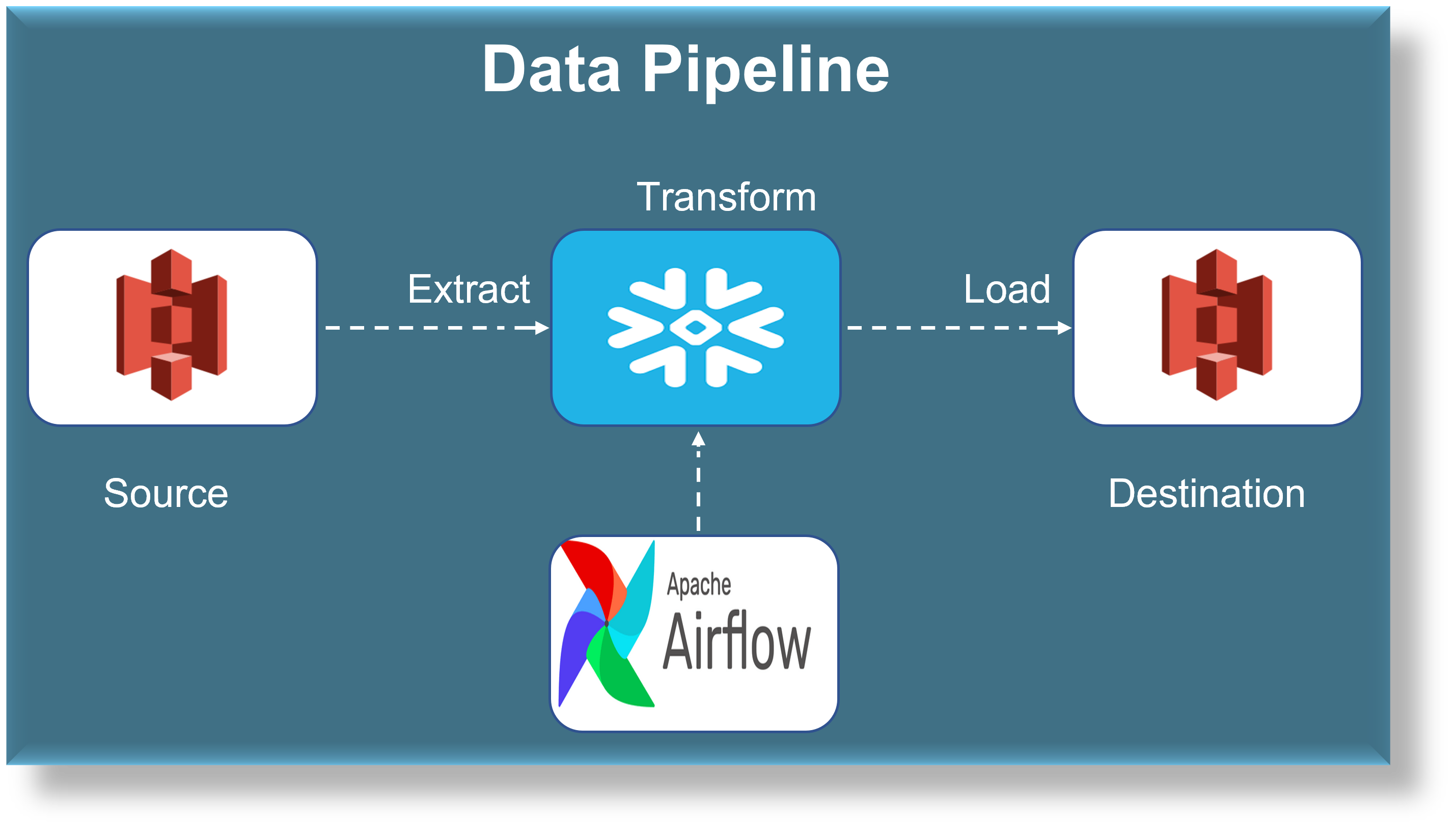 The End to End Automated Data Pipeline project aims to streamline the data processing workflow by leveraging the power of Snowflake, AWS, and Airflow. With this pipeline, users can easily extract, transform, and load data from various sources into a Snowflake data warehouse, while automating the entire process using Airflow. This project aims to reduce the time and effort required for data processing and analysis, while ensuring data accuracy and consistency.
The End to End Automated Data Pipeline project aims to streamline the data processing workflow by leveraging the power of Snowflake, AWS, and Airflow. With this pipeline, users can easily extract, transform, and load data from various sources into a Snowflake data warehouse, while automating the entire process using Airflow. This project aims to reduce the time and effort required for data processing and analysis, while ensuring data accuracy and consistency.
Spark, PySpark Interview Questions & Answers compilation
 This repository is a collection of PySpark interview questions and answers that can help you prepare for PySpark-related interviews. PySpark is a Python-based interface for Apache Spark, which is a popular big data processing framework. PySpark is widely used in industry for big data processing, machine learning, and data analytics.
This repository is a collection of PySpark interview questions and answers that can help you prepare for PySpark-related interviews. PySpark is a Python-based interface for Apache Spark, which is a popular big data processing framework. PySpark is widely used in industry for big data processing, machine learning, and data analytics.
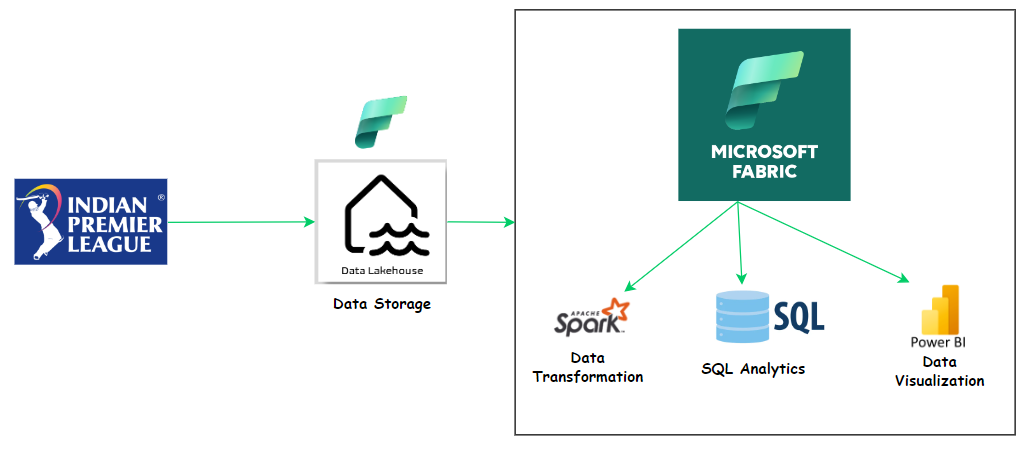
Uncovering Hidden Patterns in IPL Data with Spark and Microsoft Fabric